
En las últimas décadas, ha habido una revolución en los datos, la mayoría de compañías se han dado cuenta de que los datos les pueden aportar un valor muy elevado. Algunas de estas, han adoptado una visión data-driven gastando gran parte del presupuesto en construir una infraestructura data lake con un equipo central de datos, con la intención de conseguir este valor para sus compañías.
El funcionamiento actual de una infraestructura data lake, donde a un lado encontramos el plano de datos operacionales o transaccionales, los datos generados y utilizados por las aplicaciones. En el medio, tenemos el plano analítico o data lake, de almacenar los datos para el análisis. Finalmente, al otro lado, encontraríamos a los científicos de datos y los analistas de datos, que serían las personas encargadas en bucear dentro del data lake para encontrar los datos que necesitan para sus informes o modelos. Entre medio de estos planos y personas encontramos una gran cantidad de pipelines de extracción, transformación y carga de datos, normalmente los Data Engineers serán los encargados de mantener e implementar esta parte.
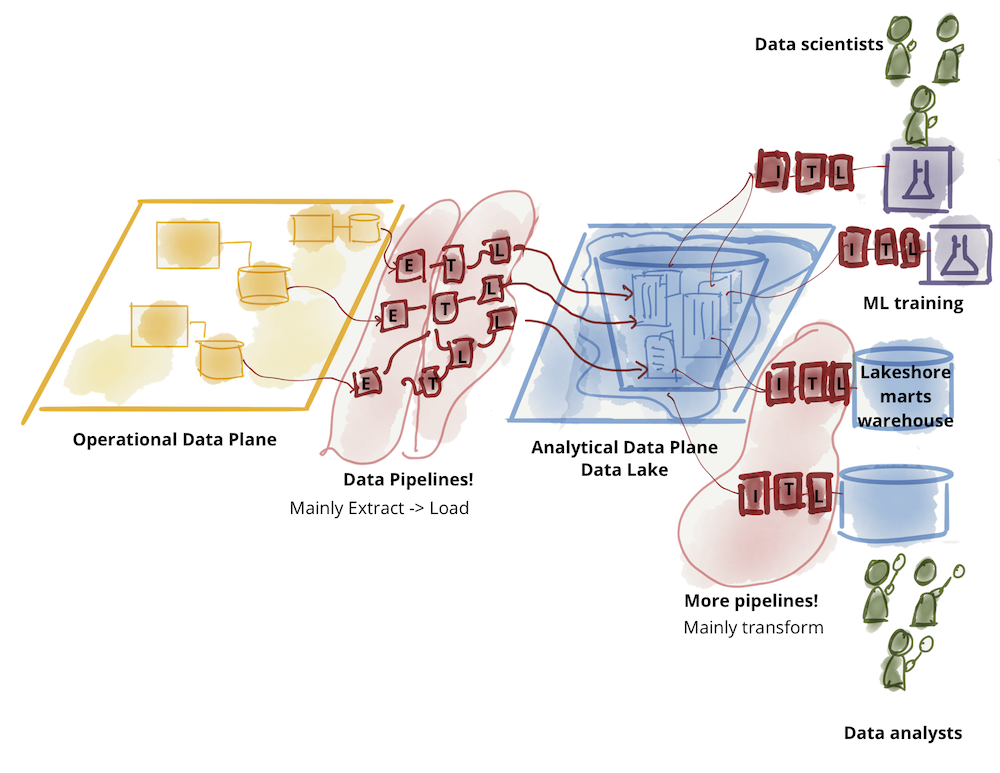
martinfowler.com/articles/data-mesh-principles.html
Pero en la actualidad se han dado cuenta de que existe alguna problemática en esta infraestructura monolítica o centralizada. El equipo central de datos, formado por los ingenieros, analistas y científicos de datos, se han vuelto un cuello de botella para muchas compañías. Este equipo empieza a tener dificultades para poder contestar todas la preguntas que vienen de gerencia u otros departamentos con la celeridad necesaria. Esto es un problema enorme en la filosofía data-driven, ya que se tienen que tomar decisiones oportunas para seguir siendo competitivos.
El equipo central de datos quiere responder con rapidez todas estas preguntas. La realidad es que tienen que dedicar mucho tiempo en solucionar errores al intentar añadir nuevos orígenes de datos, teniendo que crear nuevos pipelines de extracción, transformación y carga de datos que encajen en esta estructura. Por otro lado, tienen dificultades para servir a todos los consumidores de estos datos con datos verdaderamente de calidad, debido a que el equipo central de datos tiene que entender cada uno de los nuevos dominios para poder responder las preguntas de una forma significativa. Conseguir los conocimientos de cada dominio es una tarea difícil. En consecuencia, esta problemática deriva a no poder materializar el valor real que puede aportar la filosofía data-driven.
Además, las compañías han invertido en el domain-driven design, equipos autónomos de dominio y la arquitectura de servicios descentralizada (podéis leer el blog sobre serverless). Estos equipos de dominio poseen y conocen su dominio, incluidas las necesidades de información de la empresa. Diseñan, construyen y ejecutan sus aplicaciones web y APIs por su cuenta. Aún teniendo todo este conocimiento, estos equipos tienen que acudir al equipo central de datos para obtener los data-driven insights.
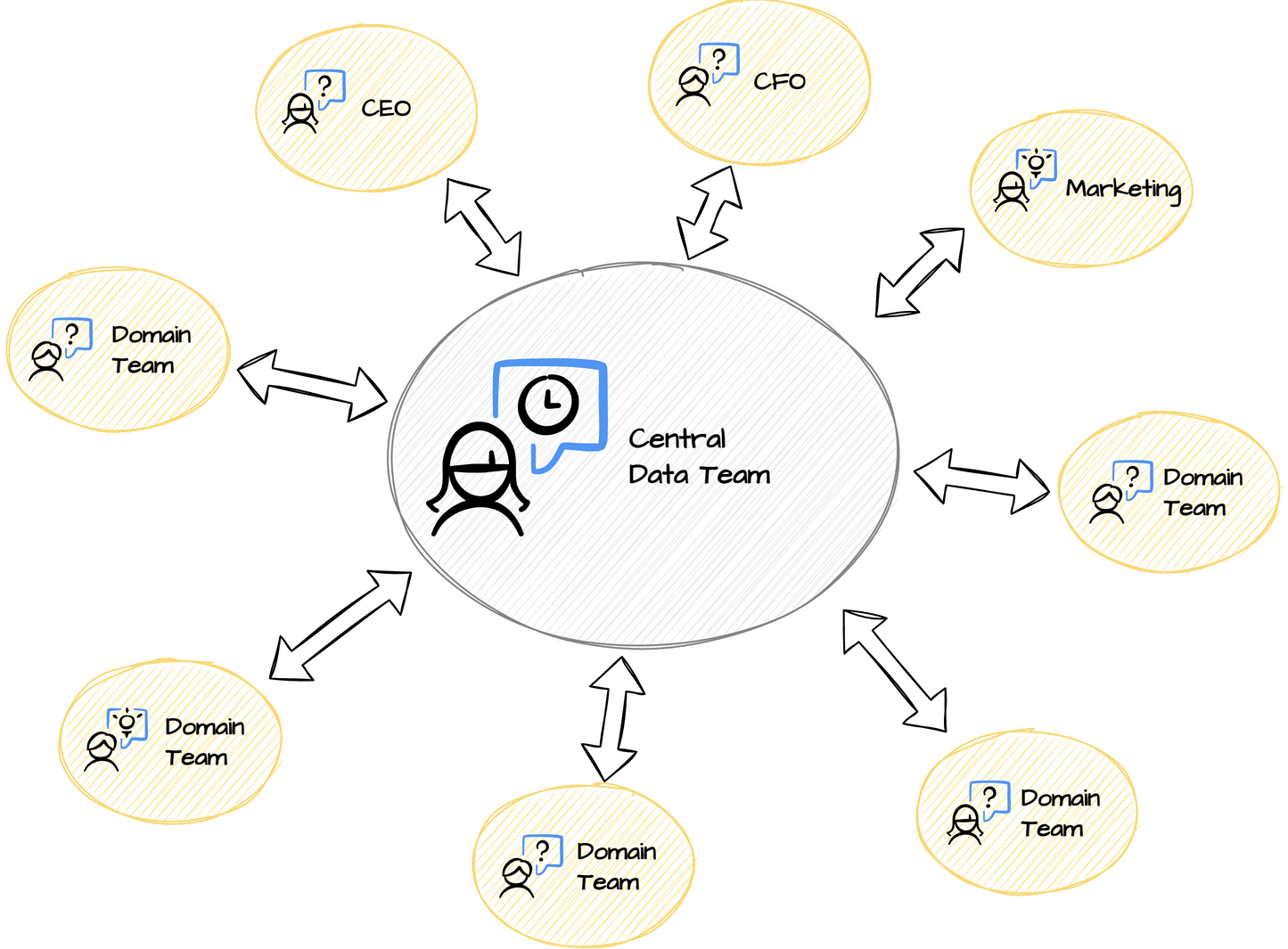
datamesh-architecture.com
A medida que la compañía va creciendo, la situación entre los equipos de dominios y el equipo central de datos empeora. La solución a esta problemática, y la idea principal de la arquitectura data mesh, es trasladar la responsabilidad de los datos del equipo central de datos a los equipos de dominio. Descentralización orientada a dominio para los datos analíticos. Una arquitectura de malla de datos permite a los equipos de dominio realizar análisis de datos entre dominios por su cuenta e interconecta los datos, de forma similar a las API en una arquitectura de microservicios.
Principios de la arquitectura Data Mesh
Data mesh, o malla de datos, es un terminó acuñado por Zhamak Dehghani en 2019 y se basa en cuatro principios fundamentales:
- El domain ownership es un principio que hace recaer la responsabilidad de cada dominio al equipo asignado a este. Según este principio, los datos analíticos deben componerse en torno a los dominios, al igual que el equipo se limitará al contexto delimitado por el sistema. Siguiendo la domain-driven distributed architecture (DDD) la responsabilidad de los datos analíticos y operacionales es del equipo del dominio, en lugar del equipo de datos centrales.
- El principio data as a product pretende adoptar la filosofía de product thinking (o pensamiento de producto) sobre los datos analíticos. Este principio nos dice que hay consumidores para los datos más allá del dominio. El domain team (o equipo del dominio) es el responsable de satisfacer las necesidades de otros dominios (consumidores) proporcionando datos de alta calidad. Es decir, los datos del dominio deben ser tratados como cualquier otra API pública.
- Self-serve data platform pretende adoptar la filosofía de platform thinking. Un equipo dedicado a la plataforma de datos proporciona funcionalidades, herramientas y sistemas independientes para construir, ejecutar y mantener productos de datos interoperables para todos los dominios. Con su plataforma, este equipo permite a los equipos de dominios consumir y crear productos de datos sin problema.
- El principio federated governance permite la interoperabilidad de todos los productos de datos a través de la estandarización, que es promovida a través de toda la malla de datos por el grupo de gobernanza. El objetivo principal es crear un ecosistema de datos que respete las normas de la organización y las regulaciones del sector.

Componentes de la arquitectura Data Mesh
Una arquitectura Data Mesh tiene un enfoque descentralizado permitiendo a los equipos de cada dominio realizar análisis de datos entre dominios por su propia cuenta. El equipo del dominio ingiere los datos operativos y construye modelos de datos analíticos para realizar sus propios análisis. Utiliza los datos analíticos para construir productos de datos basados en las necesidades de otros dominios.
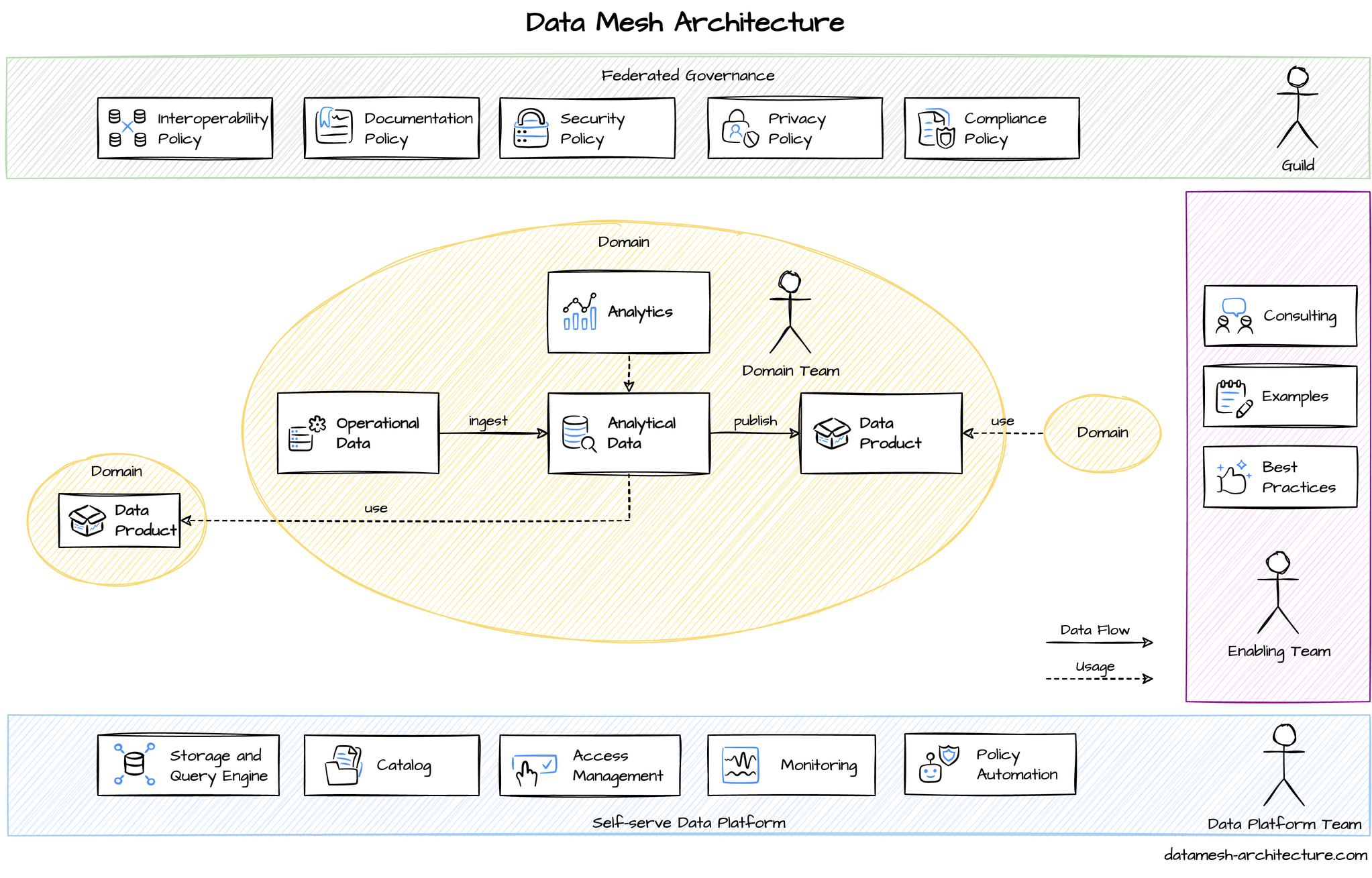
En el centro de la malla de datos encontramos los dominios, estos están relacionados entre ellos. Un dominio puede ser consumidor de un producto de datos de otro dominio y/o puede ser servidor de un producto de datos para otro dominio.
Producto de datos
Un producto de datos suele ser un conjunto de datos publicado al que pueden acceder otros dominios. Por ejemplo, una tabla o vista de una base de datos SQL, un archivo JSON con datos de eventos almacenados en un AWS S3, un informe de marketing con KPIs y gráficos en formato PDF o incluso un modelo de recomendación de películas.
Para descubrir, acceder y utilizar el producto de datos, este se describe con metadatos, incluida la información de propiedad y contacto, la ubicación y el acceso a los datos, la frecuencia de actualización y una especificación del modelo de datos.
El equipo del dominio es responsable de las operaciones del producto de datos durante todo su ciclo de vida. El equipo debe supervisar y garantizar continuamente la calidad y disponibilidad de los datos. Por ejemplo, mantener los datos sin duplicados o reaccionar ante las entradas que faltan.

Plataforma de datos
Para que los equipos de dominio no tengan que preocuparse de la implementación y mantenimiento de la infraestructura de datos requerida para añadir un producto de datos nuevo, se necesita un equipo encargado de crear una plataforma de datos de autoservicio.
Las funciones básicas de una plataforma de datos de autoservicio se pueden dividir en dos grupos, funciones analíticas y funciones de producto de datos. Las funciones analíticas permiten al equipo del dominio construir un modelo de datos analítico y realizar análisis para tomar decisiones basadas en datos. Por otro lado, la plataforma necesita funciones para ingerir, almacenar, consultar y visualizar los datos como autoservicio.
Una plataforma de datos más avanzada para la malla de datos también proporciona capacidades adicionales de productos de datos independientes del dominio para crear, supervisar, descubrir y acceder a productos de datos.
La plataforma de datos de autoservicio debe apoyar a los equipos de dominio para que puedan construir rápidamente un producto de datos, así como ejecutarlo en producción en su área aislada. La plataforma debe apoyar al equipo de dominio en la publicación de sus productos de datos para que otros equipos puedan descubrirlos. El descubrimiento requiere un punto de entrada central para todos los productos de datos descentralizados. Un catálogo de datos puede implementarse de diferentes maneras: como un wiki, un repositorio git, o incluso ya existen soluciones de proveedores para un catálogo de datos basado en la nube, como Select Star, Google Data Catalog o AWS Glue Data Catalog.
El uso real de los productos de datos, sin embargo, requiere que un equipo de dominio acceda, integre y consulte los productos de datos de otros dominios. La plataforma debe apoyar, supervisar y documentar el acceso y el uso de los productos de datos entre dominios.
Gobernanza global
Para que todas estas relaciones entre dominios se ejecuten con celeridad y con la menor complexidad posible, hay que definir una serie de políticas globales, estas serán las reglas que definirán la forma de crear nuevos productos de datos. El órgano de gobernanza global será el encargado de esta tarea.
Las políticas de interoperabilidad son el punto de partida. Permiten a otros equipos de dominio utilizar los productos de datos de forma coherente. Por ejemplo, las políticas globales podrían definir que la forma estándar de proporcionar datos es como un archivo CSV en AWS S3 en un bucket propiedad del equipo de dominio correspondiente.
A continuación, tiene que haber alguna forma de documentación para descubrir y entender los productos de datos disponibles. Una política sencilla para esto podría ser una página wiki con un conjunto predefinido de metadatos, como el propietario del producto de datos, la URL de ubicación y las descripciones de los campos CSV.
Una forma uniforme de acceder al producto de datos real de forma segura podría ser utilizando el acceso basado en roles en AWS IAM, gestionado por el equipo del dominio.
Las políticas globales, como la privacidad y la conformidad, también son comunes. Piensa en la protección de la información personal identificable (PII) o en los requisitos legales específicos del sector.
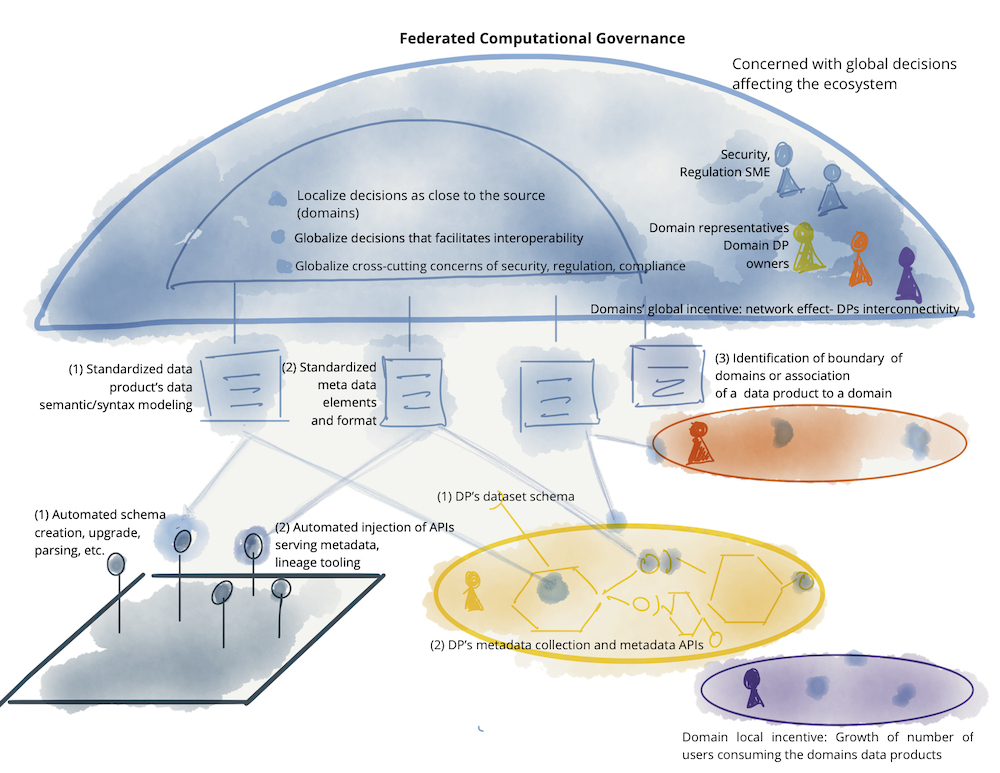
martinfowler.com/articles/data-mesh-principles.html
Equipo de apoyo
Por último, para poder ayudar a los equipos de dominio y ser los embajadores de esta arquitectura, es necesario un equipo, formado por especialistas con amplios conocimientos en análisis de datos, ingeniería de datos y la plataforma de datos de autoservicio, para poder realizar tareas de consultoría y enseñar las mejores prácticas a los equipos de dominio.
Un miembro del equipo de apoyo se une temporalmente a un equipo de dominio durante un período de tiempo limitado, como un mes, como consultor interno para entender las necesidades del equipo, establecer un entorno de aprendizaje, capacitar a los miembros del equipo en el análisis de datos y guiarlos en el uso de la plataforma de datos de autoservicio. No crean productos de datos por sí mismos.
___________________________________________________

